

Мы уже рассказывали о том, что такое психометрика и как она помогает управлять EdTech-продуктами. Предлагаем посмотреть, как это выглядит на практике. Начнем с самого простого случая — узнаем, как рассчитать долю верных ответов при одной попытке.
Бумажная книга Электронная книга

«Психометрика в EdTech: первые шаги»
На языке R
С целью демонстрации вычислений в книге автор выбрал язык программирования R — мощный инструмент для статистических вычислений и графики, созданный в 1993 году Россом Ихакой и Робертом Джентлменом. R быстро завоевал популярность и стал одним из наиболее востребованных инструментов статистического анализа и визуализации данных. Основные преимущества R заключаются в его обширной функциональности, огромном наборе доступных пакетов и активности сообщества пользователей, что делает его незаменимым для аналитиков данных. Несмотря на наличие альтернатив, таких как универсальный язык программирования Python, Дмитрий остановился на R по двум причинам.
Во-первых, R был изначально разработан для задач статистики и визуализации, что делает его более понятным и удобным именно для этих целей. Во-вторых, для новичков в области анализа данных R может оказаться более доступным благодаря своей узкой направленности на статистические задачи и логичному синтаксису. Таким образом, использование R позволяет сосредоточиться на самом важном — вычислениях — и не отвлекаться на технические детали и настройки.
Кейс: доля верных ответов при одной попытке
Представим, что студент выполняет задание, и у него только одна попытка. Можно считать, что у задания есть некое общее свойство, определяющее, насколько хорошо студенты с ним справятся. Обычно это свойство называют трудностью задания, и выражается оно по-разному.
Самый простой способ — рассчитать долю верных ответов. Для этого определяем долю верных ответов на это задание относительно общего количества ответов на него. Или, другими словами, вычисляем долю студентов, которые справились с этим заданием, от числа всех студентов, приступивших к его решению. Этот способ пришел из классической психометрической теории (или классической теории тестирования). Доля верных ответов будет иметь границы от 0 до 1, где 0 означает, что с заданием не справился никто из студентов, и 1 — что с задачей справились все студенты. Как было отмечено, доля верных ответов часто интерпретируется как трудность задания. Но важно обратить внимание, что высокие значения соответствуют простым задачам, то есть чем выше доля верных ответов, тем легче задание. Рассчитаем долю верных ответов на реальном примере.
У нас есть датасет (скачайте этот файл под названием book_dataset_1.tsv по ссылке clck.ru/3EivRg и поместите в рабочую директорию R). Он содержит несколько переменных: student_id, course_id, topic_id, lesson_id, task_id, is_correct, но для расчета доли верных ответов в этом простейшем случае нужны только три: student_id, task_id и is_correct. Первая представляет анонимизированный идентификатор студента, вторая — идентификатор задания, а третья — маркировку ответа студента на задание, где 1 — ответ верный и 0 — ответ неверный. У студентов из этого примера была только одна попытка решения, поэтому в датасете только одна пара «студент — задание» с соответствующей этой паре маркировкой ответа.
Начнем с того, что подгрузим этот датасет с помощью следующей строчки кода: df <- read.table(“book_dataset_1.tsv”, header = правда, quote = «”, sep = «\t»)
Проще всего познакомиться со структурой и содержанием датасета с помощью команды которая всегда выводит первые шесть строк данных — head(as.data.frame(df)). Выполнив ее, вы получите следующее.
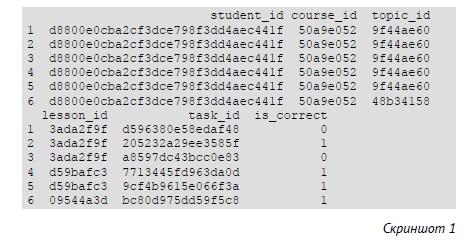
Мы видим идентификатор студента, идентификаторы курса, темы, урока и задания и маркировку ответа на задание. Мы понимаем, что студент с идентификатором d8800e0cba2cf3dce798f3dd4aec441f справился со вторым, четвертым, пятым и шестым заданиями и не справился с первым и вторым. Все шесть заданий относятся к курсу с идентификатором 50a9e052, при этом первые пять — к теме с идентификатором 9f44ae60, а шестое — к теме с идентификатором 48b34158. Первые три задания относятся к уроку 3ada2f9f, четвертое и пятое — к уроку d59bafc3 и шестое — к уроку 09544a3d. В этом продукте задания вложены в уроки, уроки в темы, темы в курсы, а курс составляет отдельный продукт (в этом датасете он один).
Далее нам нужно установить и загрузить пакет dplyr. Сделать это можно последовательно с помощью команд install.packages(“dplyr«) и library(dplyr). Первую нужно использовать один раз, так как она скачивает необходимый пакет и устанавливает его на ваш компьютер. А вторую команду важно задействовать каждый раз перед началом рабочей сессии (открыли R, воспользовались командой и далее применяем код из книги).
Читайте также:
Итак, для того чтобы рассчитать долю верных ответов, необходимо воспользоваться следующим кодом:
p_i <- df %>%
group_by(task_id) %>%
summarise(
n_Correct = sum(is_correct == 1),
n_Incorrect = sum(is_correct == 0),
p_i = round(n_Correct / (n_Correct +
n_Incorrect), 2),
.groups = «drop»
) %>%
select(task_id, p_i)
Разберем этот код последовательно. Сначала данные df группируются по заданиям с помощью команды group_by(task_id). Условно все ответы на отдельное задание раскладываются по корзинкам, каждая из которых соответствует одному заданию и маркируется его идентификатором. Затем в каждой корзинке считаем количество верных ответов (n_Correct) с помощью команды n_Correct = sum(is_correct == 1) и количество неверных ответов (n_Incorrect) с помощью команды n_Incorrect = sum(is_correct == 0). После мы можем рассчитать долю верных ответов в каждой корзинке, то есть для каждого задания, с помощью команды p_i = round (n_Correct / (n_Correct + n_Incorrect), 2). Вы видите, что мы вычисляем долю студентов, справившихся с заданием верно (n_Correct), от общего числа студентов, решавших это задание и, соответственно, давших верный и неверный ответы (n_Correct + n_Incorrect). В результате получаем значение доли верных ответов (p_i) в каждой корзинке. Эти значения помещаются в таблицу с аналогичным названием (p_i), где p — proportion (proportion correct, доля верных ответов), а i — это индекс, которым обычно обозначают задания (от слова items). В таблице имеются два столбца: первый с идентификатором задания task_id, а второй — с соответствующей ему долей верных ответов p_i.
Рассмотрим иллюстрационную (а не рассчитанную на датасете) таблицу.

Мы видим, что значения доли верных ответов варьируются. С первым заданием с идентификатором t001 справились 12% студентов, со вторым — 97%, с третьим и четвертым заданиями — 35 и 81% соответственно. Как интерпретировать эти значения?
С точки зрения учебных заданий оптимальными считаются те, доля верных решений в которых составляет 75–95%. Наша практика показывает, что оптимальных учебных результатов (например, получают более высокие оценки за проектные работы и с наибольшей вероятностью завершают обучение) добиваются те студенты, у которых доля успехов в учебном процессе составляет 75–95%. Такую долю успеха формируют учебные задания с соответствующей долей верных решений (при условии только одной попытки на их решение). Задания с долей верных решений в интервале от 50 до 75% считаются субоптимальными; с долей верных решений ниже 50% — фрустрирующими (или фрустрирующе трудными), а с долей верных решений выше 95% — скучными.
Эти градации автор подсчитывал и валидировал во время работы в международном Практикуме (ныне TripleTen), поэтому их названия в оригинале были сформулированы на английском языке: frustrating (фрустрирующие, < 50%), suboptimal (субоптимальные, от 50 до 75%), optimal (оптимальные, от 75 до 95%) и boring (скучные, выше 95%).
В одном из современных исследований, опубликованном во влиятельном журнале Nature в 2019 году, ученые из США эмпирически рассчитали оптимальную долю успехов и провалов в обучении: 85/15. Как видно, эта оптимальная категория находится ровно в середине нашей оптимальной категории (75–95%). Для удобства представим референсные значения в виде таблицы.

Если же рассуждать не об учебных, а о проверочных заданиях или экзаменах, то существуют конвенциональные границы, предложенные в классической психометрической теории (или классической теории тестирования): задания с трудностью менее 0,1 считаются очень трудными (их верно решило менее 10% выборки); с трудностью от 0,1 до 0,2 — просто трудными; диапазон от 0,2 до 0,8 наиболее продуктивен для измерений с целью подведения итогов или отбора лучших; задания с трудностью выше 0,8 оцениваются как легкие, а выше 0,9 — очень легкие.
В целом нужно заметить, что оценка доли верных ответов обычно зависит от ситуации оценивания, типа заданий, от обучающейся аудитории — иными словами, от всего того контекста, в котором идет борьба студентов с заданиями. Тут важно сделать оговорку: если в спорте стремятся победить обе стороны, то в образовании наша задача все же сбалансировать взаимодействие студентов с заданиями, ориентируясь на пользу для студента.
Узнайте больше из книги «Психометрика в EdTech: первые шаги»
Обложка поста — freepik.com










