

Данные всегда важны, а в нашу эпоху цифровой трансформации особенно. Многим приложениям с искусственным интеллектом требуются огромные объемы данных, чтобы обучить и совершенствовать алгоритмы машинного обучения по мере роста объема данных. Что такое большие данные — big data — рассказываем по книге «Цифровая трансформация».
Большие данные
Понятие big data впервые появилось в астрономии и геномике в начале 2000-х годов. В этих сферах возникали большие массивы данных. Невозможно было эффективно и недорого их обрабатывать, используя традиционную централизованную архитектуру, или вертикально масштабируемую архитектуру.
Горизонтально масштабируемая архитектура для одновременной обработки данных использует тысячи или десятки тысяч процессоров. Проектам цифровой трансформации требуется возможность оперировать big data масштаба петабайтов (1 петабайт — 1015 (квадриллион) байт). Объем не единственная характеристика big data.

Большой информационный взрыв
Получение данных — всегда долгая и кропотливая работа. Организации собирали статистические данные, в основе которых лежали небольшие выборки (сотни или тысячи записей о транзакциях), и на их основе делали выводы обо всей картине в целом. Из-за малых объемов данных специалисты тратили много времени и сил на верификацию, чтобы исключить сведения, которые могли исказить результаты.
Облака дают неограниченные возможности для проведения вычислений и хранения информации. Появляется программное обеспечение, разработанное для параллельной обработки данных в огромных масштабах. Организациям больше не нужно ограничивать и отбирать исходные данные для анализа. Теперь выпадающие из общего ряда или нерелевантные данные грамотно встроены в анализ big data.

Цифровая трансформация
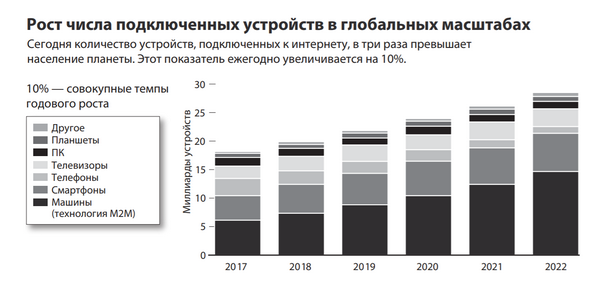
В итоге более 20 миллиардов подключенных к интернету смартфонов, датчиков и прочих устройств генерируют постоянно растущий поток данных, ежегодные объемы которого измеряются в зеттабайтах (1 зеттабайт данных поместится на 250 миллиардах DVD-дисков). Сегодня компании могут делать выводы на основе доступных данных практически в режиме реального времени.
Возможность применять искусственный интеллект к обработке всего объема сырых данных привела к еще одной перемене. Больше нет необходимости в экспертах для построения гипотез, объясняющих причины того или иного события.
Например, для определения причины просрочки платежей по ипотеке больше не нужен опытный специалист по кредитованию. Система может изучить причины и их относительную важность с высокой степенью достоверности благодаря анализу всех доступных данных по неплатежам других клиентов.
У этого явления далеко идущие последствия. Для выявления неисправностей двигателя больше не нужен опытный механик. Для выявления начальной стадии диабета у пациента больше не нужен опытный врач. Для определения оптимального места для бурения нефтяной скважины больше не нужен инженер-геолог.
Появление машинного обучения в сочетании с неограниченной вычислительной мощностью породило новый класс алгоритмов, решающих проблемы, которые когда-то считались неразрешимыми. Например, оценка риска поломки самолетного двигателя. Определив все важные входные данные (летные часы, условия полета, записи о техническом обслуживании, температуру двигателя, давление масла) и выбрав достаточно большое количество случаев поломки двигателя (то есть выходные данные), алгоритм не только предупредит о поломке, но и определит ее причины. Для этого не нужно быть специалистом по материаловедению или термодинамике. Достаточно лишь нужных данных в большом объеме.
Подробнее: «Цифровая трансформация».










